
With the annual ISC Excessive Efficiency supercomputing convention kicking off this week, Intel is considered one of a number of distributors making bulletins timed with the present. Because the crown jewels of the corporate’s HPC product portfolio have launched within the final a number of months, the corporate doesn’t have any main new silicon bulletins to make alongside this 12 months’s present – and sadly Aurora isn’t but up and operating to take a shot on the High 500 record. So, following a tumultuous 12 months so far that has seen vital shifts in Intel’s GPU roadmap particularly, the corporate is utilizing ISC to recompose itself and use the backdrop of the present to put out a recent roadmap for HPC prospects.
Most notably, Intel is utilizing this chance to raised clarify a few of the {hardware} improvement selections the corporate has made this 12 months. That features Intel’s pivot on Falcon Shores, reworking it from XPU right into a pure GPU design, as effectively to some extra high-level particulars of what is going to ultimately develop into Intel’s subsequent HPC-class GPU. Though Intel would clearly be completely comfortable to maintain promoting CPUs, the corporate has (and continues to) realign for a diversified market the place their high-performance prospects want extra than simply CPUs.
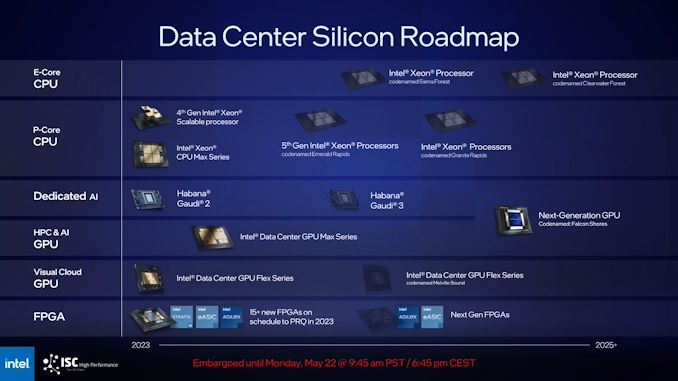
CPU Roadmap: Emerald Rapids and Granite Rapids Xeons within the Works
As famous earlier, Intel isn’t asserting any new silicon right now throughout any a part of their HPC portfolio. So Intel’s newest HPC roadmap is actually a condensed model of their newest knowledge heart roadmap, which was first laid out to buyers in the direction of the top of March. HPC is, in any case, a subset of the information heart market, so the HPC roadmap displays this.
I gained’t go into Intel’s CPU roadmap an excessive amount of right here, since we simply coated it a few months in the past, however the firm is as soon as once more reiterating the rapid-fire run they intend to make via their Xeon merchandise over the subsequent 18 months. Sapphire Rapids is only some months into delivery, however Intel intends to have its same-platform successor, Emerald Rapids, prepared for supply in This fall. In the meantime Granite Rapids, Intel’s first P-Core Xeon on the Intel 3 course of, will launch with its new platform in 2024. Granite may even be Intel’s first product to assist larger bandwidth MCR DIMM reminiscence, which was equally demonstrated again in March.

Notably right here, regardless of the HPC viewers of ISC, Intel nonetheless hasn’t introduced a successor to the current-generation HBM-equipped Sapphire Rapids Xeon with HBM – which the corporate manufacturers because the Xeon Max Collection. Intel’s moderately pleased with the half – declaring that it’s the one x86 processor with HBM each time they get the possibility – and it’s a core a part of the Aurora supercomputer. We had been anticipating its successor to fall into place with Falcon Shores again when it was an XPU, however since Falcon pivoted to being a GPU, there’s been no additional signal of the place one other HBM Xeon will land on Intel’s roadmap.
Within the meantime, Intel is raring to show to the ISC viewers the efficiency advantages of getting a lot excessive bandwidth reminiscence on-package with the CPU cores – and particularly earlier than AMD launches their EPYC Genoa-X processors with their supersized, 1GB+ L3 caches. To that finish Intel has revealed a number of recent benchmarks evaluating Xeon Max Collection processors to EPYC 7000 and 9000 sequence chips, which as they’re vendor benchmarks I gained’t get into right here, however you could find within the gallery beneath.
GPU Roadmap Right this moment: Ponte Vecchio Now Delivery, Further SKUs To Launch in Coming Months
The GPU counterpart to Sapphire Rapids with HBM for the HPC crowd is Intel’s Knowledge Middle GPU Max sequence, in any other case often called Ponte Vecchio. The massively tiled chip remains to be in contrast to every other GPU in the marketplace, and Intel’s IFS foundry arm is kind of proud to level out to potential prospects that they’re capable of reliably assemble one of the crucial superior chips in the marketplace, with practically 4 dozen chiplets to completely place to carry the entire thing collectively.
Ponte Vecchio has had an extended and exhausting improvement cycle for Intel and its prospects alike, so that they’re taking a little bit of a victory lap at ISC to have a good time that accomplishment. In fact, Ponte Vecchio is just the start of Intel’s HPC GPU efforts, and never the top. So they’re nonetheless within the means of build up the OneAPI software program and gear ecosystem to assist the {hardware} – all whereas being conscious of the truth that they want a robust software program ecosystem to match rival NVIDIA, and to capitalize on AMD’s present shortcomings.
Regardless of being practically a era late, Intel surprisingly has some benchmarks evaluating Ponte Vecchio to NVIDIA’s new Hopper architecture-based H100 accelerators. With that mentioned, these are for Intel’s top-end OAM-based modules towards H100 PCIe playing cards; so cherry choosing apart, it stays to be seen simply how effectively issues would look with a extra apples-to-apples {hardware} comparability.

Talking of OAM modules, Intel is utilizing the present to announce a brand new 8-way Common Baseboard (UBB) for Ponte Vecchio. Becoming a member of Intel’s current 4-way UBB, the x8 UBB will enable for 8 Knowledge Middle Max GPU modules to be positioned on a single server board, just like what NVIDIA does with their HGX service boards. If Intel is to go toe-to-toe with NVIDIA and to seize a part of the HPC GPU market, then that is another space the place they’re going to want to match NVIDIA’s {hardware} choices. Up to now Supermicro and Inspur are signed as much as distribute servers utilizing the brand new x8 UBB, and if issues go their manner, these shouldn’t be Intel’s solely prospects.

Together with the UBB announcement, Intel can also be offering for the primary time an in depth, month-by-month roadmap for Knowledge Middle Max GPU product availability. Now that Intel has practically happy their Aurora order, the primary components have been vaguely obtainable to pick prospects, however now we get to see the place issues stand in a bit extra element. Per that roadmap, OEMs must be prepared to start delivery 4-way GPU methods in June, whereas 8-way methods will likely be a month behind that in July. In the meantime OEM methods utilizing the PCIe model of Ponte Vecchio, the Knowledge Middle GPU Max 1100, will likely be obtainable in July. Lastly, a detuned model of Ponte Vecchio for “totally different markets” (learn: China) will likely be obtainable in This fall of this 12 months. Particulars on this half are nonetheless slim, however it would have lowered I/O bandwidth to satisfy US export necessities.
GPU Roadmap Tomorrow: All Roads Result in Falcon Shores
Wanting previous the present iteration of the Knowledge Middle GPU Max sequence and Ponte Vecchio, the subsequent GPU within the pipeline for Intel’s HPC prospects is Falcon Shores. As we detailed again in March, Falcon Shores will likely be taking up a considerably totally different function in life than Intel first supposed, following the cancellation of Rialto Bridge, Ponte Vecchio’s direct descendent. As an alternative of being Intel’s first mixed CPU + GPU product – a versatile XPU that may use a mixture of CPU and GPU tiles – Falcon is now going to be a purely GPU product. Sadly, it’s additionally choosing up a 12 months’s delay within the course of, pushing it to 2025, which means that Intel’s HPC GPU lineup is only Ponte primarily based for the subsequent couple of years.
The cancellation of Rialto Bridge and the de-XPUing of Falcon Shores created a great deal of consternation inside the media and HPC neighborhood, so Intel is utilizing this second to get their messaging so as, each by way of why they pivoted on Falcon Shores, and simply what it would entail.
The lengthy and wanting the story there may be that Intel has determined that they mistimed the marketplace for their first XPU, and that Falcon Shores as an XPU would have wound up being untimely. In Intel’s collective thoughts, as a result of these merchandise supply a set ratio of CPU cores to GPU cores (vis a vie the variety of tiles used), they’re finest suited to workloads that intently match these {hardware} allocations.
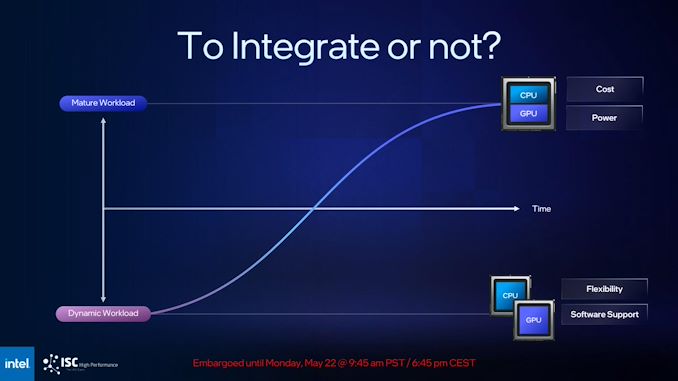
And what workloads are these? Properly, that finally ends up being the 100B transistor query. Intel was anticipating the market to be extra settled than it truly has been – that’s to say, it’s been extra dynamic than Intel was anticipating – which Intel believes makes an XPU with its fastened ratios tougher to match to workloads, and tougher to promote to prospects. Because of this, Intel has backed off on their integration plans, resulting in the all-GPU Falcon Shores.

Now with that mentioned, Intel is making it clear that they’re not aborting the thought of an XPU totally; solely that Falcon Shores in 2024/2025 shouldn’t be the fitting time for it. So, Intel can also be confirming that they are going to be creating a tile-based XPU as a future, post-Falcon Shores product (probably as Falcon Shores’ successor?). There aren’t any additional particulars on that future XPU than this, however for now, Intel nonetheless desires to get to CPU/GPU integration as soon as they deem the workloads and the market are prepared. This additionally signifies that Intel is successfully ceding the blended CPU-GPU accelerator market to AMD (and to a lesser extent, NVIDIA) for at the least a couple of extra years, so make of that what you’ll with Intel’s official rationale for delaying their very own XPU.

As for the all-GPU Falcon Shores, Intel is sharing only a hair extra in regards to the design and capabilities of their next-generation PC GPU. As you’d count on from a design that began as a tiled product, Falcon stays a chiplet-based design. Although it’s unclear simply what sorts of chiplets Intel will use (in the event that they’ll be homogenous GPU blocks or not), they are going to be paired with HBM3 reminiscence, and what Intel phrases as “I/O designed to scale.” In mild of Intel’s choice to delay XPUs, this will likely be how they ship a versatile CPU-to-GPU ratio for his or her HPC prospects by way of the tried and true manner: add as many GPUs to your system as you want.
Falcon Shores may even assist Ethernet switching as a typical characteristic, which will likely be a serious part in supporting the type of very massive meshes that prospects are constructing with their supercomputers right now. And since these components will likely be discrete GPUs, Intel will likely be embracing CXL to ship further performance to system designers and programmers. Given the timing, CXL 3.0 performance is a protected wager, with issues like P2P DMA and superior material assist going hand-in-hand with what the HPC market has been constructing in the direction of.
And with a couple of years of expertise behind them at that time, Intel expects to have the ability to leverage OneAPI even tougher. Particularly as they’ll want the assistance of software program to summary the CPU-GPU I/O hole that Falcon Shores the XPU was in any other case going to have the ability to shut in {hardware}.
Aurora Replace: 10K+ Blades Delivered, Further Specs Disclosed
Lastly, Intel can also be providing an replace on Aurora, their Sapphire Rapids with HBM + Ponte Vecchio primarily based supercomputer for Argonne Nationwide Laboratory. A product of two delayed processors, Aurora is itself a delayed system that Intel has been working to atone for. When it comes to the {hardware} itself, the sunshine is in sight on the finish of the tunnel, as Intel is wrapping up supply of Aurora’s compute blades.
As of right now, Intel has delivered over 10,000 blades for Aurora, very near the ultimate anticipated tally for the system of 10,624 nodes. Sadly, delivered and put in aren’t fairly the identical issues right here; so whereas Argonne has a lot of the {hardware} in hand, Aurora isn’t able to make a run on the Top500 supercomputer record, leaving the AMD-based Frontier system to carry the highest spot for an additional 6 months.
On the plus aspect, with Aurora’s {hardware} shipments practically full, Intel is lastly disclosing a extra detailed abstract of Aurora’s {hardware} specs. This contains not solely the variety of nodes and the CPUs and GPUs inside them, but in addition the varied quantities of reminiscence and storage obtainable to the supercomputer.
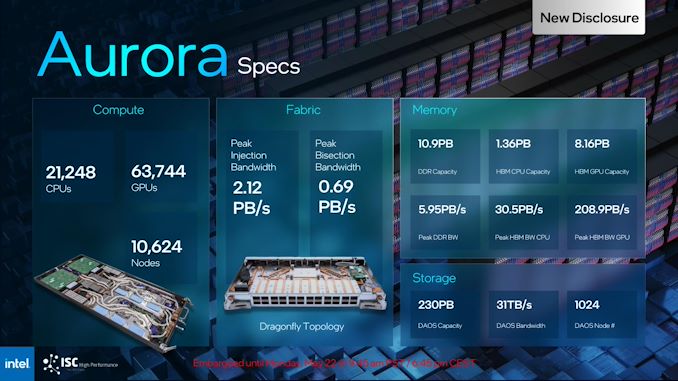
With 2 CPUs and 6 GPUs in every node, the totally assembled Aurora will likely be comprised of 21,248 Sapphire Rapids CPUs and 63,744 Ponte Vecchio GPUs, and as beforehand disclosed, the height efficiency of the system is anticipated to be in extra of two ExaFLOPS of FP64 compute. Apart from the 128GB of HBM on every GPU and 64GB of HBM on every CPU, there’s a further 1 TB of DDR5 reminiscence put in on every node. Peak bandwidth will come from the HBM for the GPUs, at 208.9PB/second, although even the “gradual” DDR5 remains to be an mixture 5.95PB/second.

And since no supercomputer announcement could be full with out some point out of AI, Intel and Argonne are creating a generative/large-language-model AI to be used on Aurora, which they’re calling for now the Generative AI for Science. The mannequin will likely be developed particularly for scientific use, and Intel expects it to be a 1 trillion parameter mannequin (which might place it between GPT-3 and GPT-4 in measurement). The expectation is that they’ll use Aurora for each the coaching and inference of this mannequin, although within the case of the latter, that might presumably be only a fraction of the system given the a lot decrease system necessities for inference.
At this level Aurora stays on schedule for a launch this 12 months. Apart from starting manufacturing use, Intel expects that Aurora will be capable to place on the Top500 record for its November replace, at which level it’s anticipated to develop into essentially the most highly effective supercomputer on this planet.







")

{kind=link}