
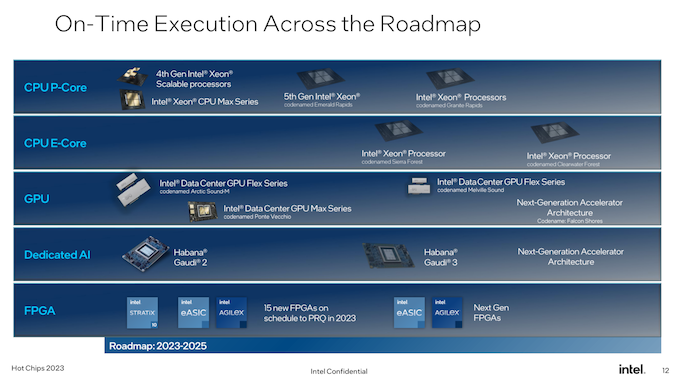
With the annual Sizzling Chips convention going down this week, most of the trade’s largest chip design corporations are on the present, speaking about their newest and/or upcoming wares. For Intel, it’s a case of the latter, as the corporate is at Sizzling Chips to speak about its subsequent era of Xeon processors, Granite Rapids and Sierra Forest, that are set to launch in 2024. Intel has beforehand revealed this processors on its knowledge heart roadmap – most just lately updating it in March of this yr – and for Sizzling Chips the corporate is providing a bit extra in the way in which of technical particulars for the chips and their shared platform.
Whereas there’s no such factor as an “unimportant” era for Intel’s Xeon processors, Granite Rapids and Sierra Forest promise to be one in all Intel’s most vital up to date to the Xeon Scalable {hardware} ecosystem but, because of the introduction of area-efficient E-cores. Already a mainstay on Intel’s shopper processors since 12th era Core (Alder Lake), with the upcoming subsequent era Xeon Scalable platform will lastly carry E-cores over to Intel’s server platform. Although not like shopper components the place each core sorts are combined in a single chip, Intel goes for a purely homogenous technique, giving us the all P-core Granite Rapids, and the all E-core Sierra Forest.
As Intel’s first E-core Xeon Scalable chip for knowledge heart use, Sierra Forest is arguably a very powerful of the 2 chips. Fittingly, it’s Intel’s lead car for his or her EUV-based Intel 3 course of node, and it’s the primary Xeon to come back out. In keeping with the corporate, it stays on monitor for a H1’2024 launch. In the meantime Granite Rapids can be “shortly” behind that, on the identical Intel 3 course of node.
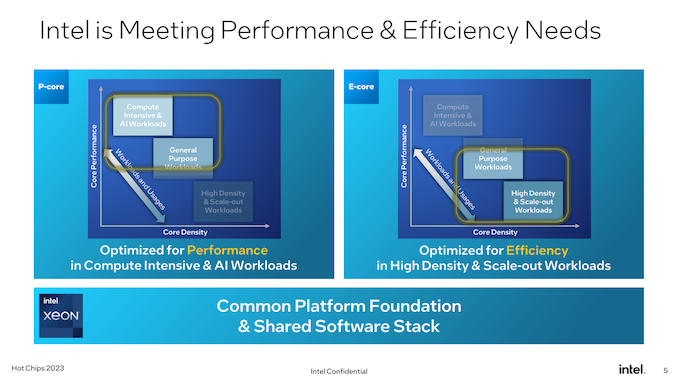
As Intel’s slated to ship two somewhat completely different Xeons in a single era, a giant aspect of the subsequent era Xeon Scalable platform is that each processors will share the identical platform. This implies the identical socket(s), the identical reminiscence, the identical chiplet-based design philosophy, the identical firmware, and so on. Whereas there are nonetheless variations, significantly in the case of AVX-512 assist, Intel is making an attempt to make these chips as interchangeable as attainable.
As introduced by Intel again in 2022, each Granite and Sierra are chiplet-based designs, counting on a mixture of compute and I/O chiplets which are stitched collectively utilizing Intel’s energetic EMIB bridge expertise. Whereas this isn’t Intel’s first dance with chiplets within the Xeon area (XCC Sapphire Rapids takes that honor), this can be a distinct evolution of the chiplet design by utilizing distinct compute/IO chiplets as a substitute of sewing collectively in any other case “full” Xeon chiplets. Amongst different issues, because of this Granite and Sierra can share the frequent I/O chiplet (constructed on the Intel 7 course of), and from a producing standpoint, whether or not a Xeon is Granite or Sierra is “merely” a matter of which sort of compute chiplet is positioned down.
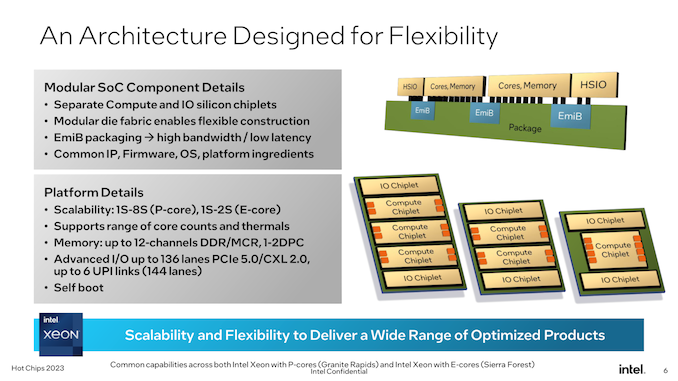
Notably right here, Intel is confirming for the primary time that the subsequent gen Xeon Scalable platform is getting self-booting capabilities, making it a real SoC. With Intel putting all the obligatory I/O options wanted for operation inside the I/O chiplets, an exterior chipset (or FPGA) is just not wanted to function these processors. This brings Intel’s Xeon lineup nearer in performance to AMD’s EPYC lineup, which has been equally self-booting for some time now.
Altogether, the subsequent gen Xeon Scalable platform will assist as much as 12 reminiscence channels, scaling with the quantity and capabilities of the compute dies current. As beforehand revealed by Intel, this platform would be the first to assist the brand new Multiplexer Mixed Ranks (MCR) DIMM, which primarily gangs up two units/ranks of reminiscence chips with a view to double the efficient bandwidth to and from the DIMM. With the mixture of upper reminiscence bus speeds and extra reminiscence channels general, Intel says the platform can provide 2.8x as a lot bandwidth as present Sapphire Rapids Xeons.
As for I/O, a max configuration Xeon will be capable to provide as much as 136 lanes basic I/O, in addition to as much as 6 UPI hyperlinks (144 lanes in complete) for multi-socket connectivity. For I/O, the platform helps PCIe 5.0 (why no PCIe 6.0? We have been advised the timing didn’t work out), in addition to the newer CXL 2.0 customary. As is historically the case for Intel’s big-core Xeons, Granite Rapids chips will be capable to scale as much as 8 sockets altogether. Sierra Forest, however, will solely be capable to scale as much as 2 sockets, owing to the variety of CPU cores in play in addition to the completely different use circumstances Intel is anticipating of their clients.
Together with particulars on the shared platform, Intel can be providing for the primary time a high-level overview of the architectures used for the E-cores and the P-cores. As has been the case for a lot of generations of Xeons now, Intel is leveraging the identical primary CPU structure that goes into their shopper components. So Granite and Sierra might be regarded as a deconstructed Meteor Lake processor, with Granite getting the Redwood Cove P-cores, whereas Sierra will get the Crestmont E-Cores.

As famous earlier than, that is Intel’s first foray into providing E-cores for the Xeon market. Which for Intel, has meant tuning their E-core design for knowledge heart workloads, versus the consumer-centric workloads that outlined the earlier era E-core design.
Whereas not a deep-dive on the structure itself, Intel is revealing that Crestmont is providing a 6-wide instruction decode pathway in addition to an 8-wide retirement backend. Whereas not as beefy as Intel’s P-cores, the E-core is just not by any means a light-weight core, and Intel’s design choices mirror this. Nonetheless, it’s designed to be way more environment friendly each by way of die area and power consumption than the P cores that may go into Granite.
The L1 instruction cache (I-cache) for Crestmont can be 64KB, the identical dimension as on Gracemont. In the meantime, new to the E-core lineup with Crestmont, the cores can both be packaged into 2 or 4 core clusters, not like Gracemont at the moment, which is just out there as a 4 core cluster. That is primarily how Intel goes to regulate the ratio of L2 cache to CPU cores; with 4MB of shared L2 whatever the configuration, a 2-core cluster affords every core twice as a lot L2 per core as they’d in any other case get. This primarily offers Intel one other knob to regulate for chip efficiency; clients who want a barely increased performing Sierra design (somewhat than simply maxing out the variety of CPU cores) can as a substitute get fewer cores with the upper efficiency that comes from the successfully bigger L2 cache.
And at last for Sierra/Crestmont, the chip will provide as near instruction parity with Granite Rapids as attainable. This implies BF16 knowledge sort assist, in addition to assist for varied instruction units equivalent to AVX-IFMA and AVX-DOT-PROD-INT8. The one factor you gained’t discover right here, moreover an AMX matrix engine, is assist for AVX-512; Intel’s ultra-wide vector format is just not part of Crestmont’s characteristic set. In the end, AVX10 will assist to maintain this downside, however for now that is as shut as Intel can get to parity between the 2 processors.
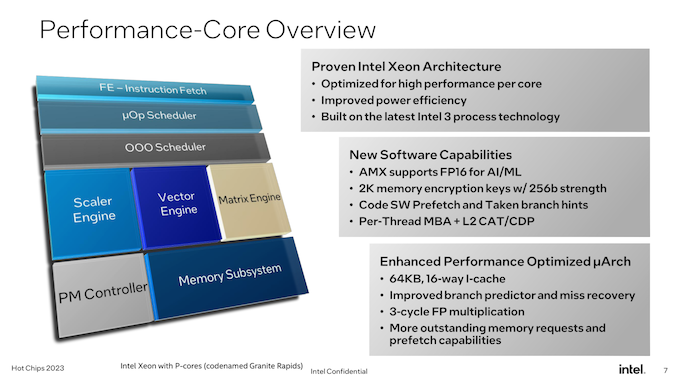
In the meantime, for Granite Rapids we’ve got the Redwood Cove P-core. The normal coronary heart of a Xeon processor, Redwood/Granite aren’t as massive of a change for Intel as Sierra Forest is. However that doesn’t imply they’re sitting idly by.
By way of microarchitecture, Redwood Cove is getting the identical 64KB I-cache as we noticed on Crestmont, which not like the E-cores, is 2x the capability of its predecessor. It’s uncommon for Intel to the touch I-cache capability (because of balancing hit charges with latency), so this can be a notable change and will probably be attention-grabbing to see the ramifications as soon as Intel talks extra about structure.
However most notably right here, Intel has managed to additional shave down the latency of floating-point multiplication, bringing it from 4/5 cycles down to only 3 cycles. Elementary instruction latency enhancements like these are uncommon, in order that they’re at all times welcome to see.
In any other case, the remaining highlights of the Redwood Cove microarchitecture are department prediction and prefetching, that are typical optimization targets for Intel. Something they’ll do to enhance department prediction (and cut back the price of uncommon misses) tends to pay comparatively massive dividends by way of efficiency.
Extra relevant to the Xeon household specifically, the AMX matrix engine for Redwood Cove is gaining FP16 assist. FP16 isn’t as fairly as closely used because the already-supported BF16 and INT8, but it surely’s an enchancment to AMX’s flexibility general.
Reminiscence encryption assist can be being improved. Granite Rapids’ taste of Redwood Cove will assist 2048, 256-bit reminiscence keys, up from 128 keys on Sapphire Rapids. Cache Allocation Expertise (CAT) and Code and Information Prioritization (CDP) performance are additionally getting some enhancements right here, with Intel extending them to have the ability to management what goes in to the L2 cache, versus simply the LLC/L3 cache in earlier implementations.
In the end, it goes with out saying that Intel believes they’re well-positioned for 2024 and past with their upcoming Xeons. By enhancing efficiency on the top-end P-core Xeons, whereas introducing E-core Xeons for purchasers who simply want plenty of lighter CPU cores, Intel believes they’ll deal with the whole market with two CPU core sorts sharing a single frequent platform.
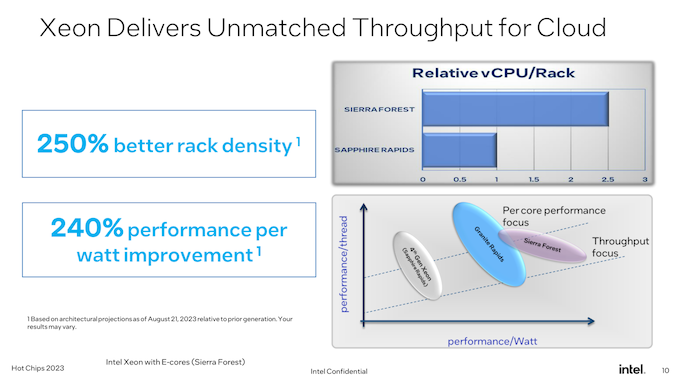
Whereas it’s nonetheless too early to speak about particular person SKUs for Granite Rapids and Sierra Forest, Intel has advised us that core counts general are going up. Granite Rapids components will provide extra CPU cores than Sapphire Rapids (up from 60 for SPR XCC), and, in fact, at 144 cores Sierra will provide much more than that. Notably, nevertheless, Intel gained’t be segmenting the 2 CPU strains by core counts – Sierra Forest can be out there in smaller core counts as nicely (not like AMD’s EPYC Zen4c Bergamo chips). This displays the completely different efficiency capabilities of the P and E cores, and, little question, Intel trying to absolutely embrace the scalability that comes from utilizing chiplets.
And whereas Sierra Forest will already go to 144 CPU cores, Intel additionally made an attention-grabbing remark in our pre-briefing that they might have gone increased with core counts for his or her first E-core Xeon Scalable processor. However the firm determined to prioritize per-core efficiency a bit extra, ensuing within the chips and core counts we’ll be seeing subsequent yr.

Above all else – and, maybe, letting advertising take the wheel a bit too lengthy right here for Sizzling Chips – Intel is hammering dwelling the truth that their next-generation Xeon processors stay on-track for his or her 2024 launch. It goes with out saying that Intel is simply now recovering from the large delays in Sapphire Rapids (and knock-on impact to Emerald Rapids), so the corporate is eager to guarantee clients that Granite Rapids and Sierra Forest is the place Intel’s timing will get again on monitor. Between earlier Xeon delays and taking so lengthy to carry to market an E-core Xeon Scalable chip, Intel hasn’t dominated within the knowledge heart market prefer it as soon as did, so Granite Rapids and Sierra Forest are going to mark an vital inflection level for Intel’s knowledge heart choices going ahead.

")








{kind=link}